
{kind=link}

Der Moment, in dem Europa die Regeln neu schrieb
Es war der 2. Dezember 2025, kurz nach Mitternacht europäischer Zeit, als Mistral AI etwas tat, das die Silicon-Valley-Orthodoxie frontal angreift: Sie verschenkten ihr bestes Modell.
Nicht „open-washed“. Nicht „limited commercial“. Apache 2.0. Die radikalste Open-Source-Lizenz, die es gibt. Nimm es, fork es, verkauf es, mach damit was du willst.
Während OpenAI seine GPT-Modelle hinter API-Walls vergräbt und Anthropic Claude als Premium-Service positioniert, stellt ein französisches Startup mit gerade mal 200 Mitarbeitern die grundlegendste Frage der KI-Industrie: Was wenn die Zukunft nicht in der Zentralisierung liegt, sondern in der Verteilung?
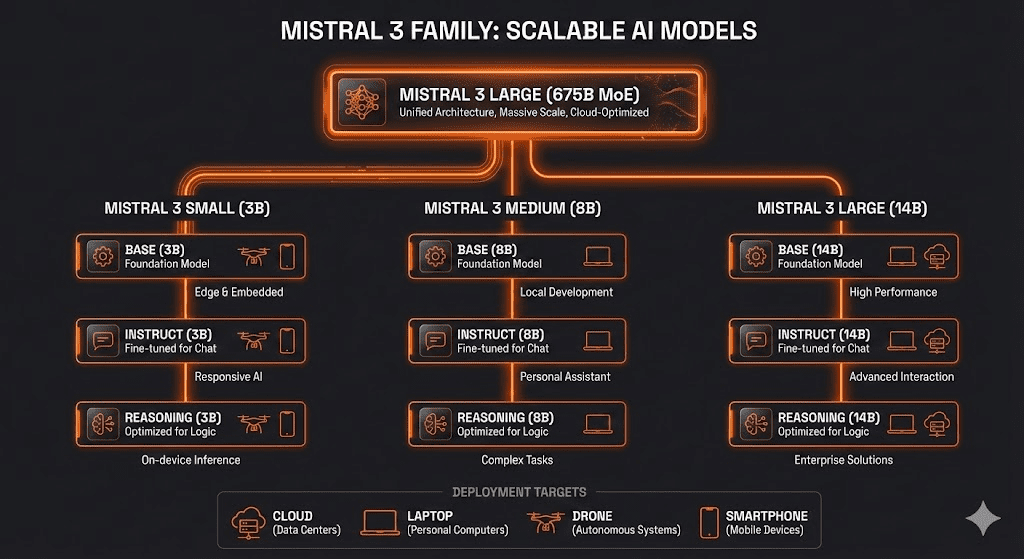
Die Architektur: Warum 94% eines Modells schlafen dürfen
Mistral Large 3 ist ein Monster – 675 Milliarden Parameter, trainiert auf 3.000 von NVIDIAs neuesten H200-GPUs. Aber hier wird es interessant: Bei jedem einzelnen Token, den das Modell verarbeitet, aktivieren sich nur 41 Milliarden davon. Der Rest? Schläft.
Das ist keine Schwäche. Das ist das Design.
Eine Sparse Mixture of Experts (MoE) Architektur funktioniert wie ein Krankenhaus-Team: Nicht jeder Spezialist muss bei jeder OP im Raum stehen. Der Kardiologe kommt, wenn’s ums Herz geht. Der Neurologe, wenn’s um Nerven geht. Bei Mistral Large 3 entscheidet ein Router-Netzwerk bei jedem Token neu, welche „Experten“ gebraucht werden.
Die Konsequenz? Ein Modell, das die Qualität eines 675B-Modells liefert, aber nur die Rechenkosten eines 41B-Modells verursacht. Das ist nicht clever. Das ist disruptiv.
Die Ministral-Armee: KI kommt nach Hause
Aber Mistral Large 3 ist nur die Speerspitze. Die eigentliche Revolution versteckt sich in den neun kleinen Modellen der Ministral-3-Serie:
Die 3B-Variante läuft mit 4-Bit-Quantisierung auf 4GB VRAM. Das bedeutet: Ein 2015er MacBook Air kann dieses Modell lokal ausführen. Keine Cloud. Keine API-Kosten. Keine Daten, die irgendwohin fließen.
Für die geopolitischen Implikationen braucht man keine Phantasie: Länder unter Sanktionen, Organisationen mit Datensouveränitäts-Anforderungen, Unternehmen in regulierten Branchen – sie alle bekommen plötzlich Zugang zu Frontier-KI, ohne sich an Silicon Valley binden zu müssen.
Die HSBC-Connection: Warum eine Bank das Modell hostet, nicht kauft
Einen Tag vor dem Mistral-3-Launch – am 1. Dezember 2025 – kündigte HSBC eine „mehrjährige strategische Partnerschaft“ mit dem französischen Startup an. Die Formulierung „selbst gehostete KI-Modelle, die auf HSBCs internen Technologiesystemen laufen“ ist kein Marketing-Sprech. Das ist eine regulatorische Notwendigkeit.
Für eine Bank mit 3,2 Billionen Dollar Assets, die unter GDPR operiert und Kundendaten wie das eigene Leben schützen muss, ist die Frage nicht „Welches Modell ist am besten?“ Die Frage ist: „Welches Modell kann ich kontrollieren?“
Claude 4.5? Proprietär. Eine Black Box.
GPT-5.1? Abhängig von OpenAIs Infrastruktur.
Mistral Large 3? Open Source. Auditierbar. On-Premise deploybar.
Georges Elhedery, HSBCs Group CEO, formulierte es so: Die Partnerschaft werde Mitarbeitern Werkzeuge geben, um „zu innovieren, tägliche Aufgaben zu vereinfachen und Zeit freizusetzen, um für Kunden zu liefern.“
Das klingt nach Corporate-Speak. Aber übersetzt heißt es: Wir können jetzt KI nutzen, ohne unsere Daten an amerikanische Server zu schicken.
Die 14-Milliarden-Dollar-Wette
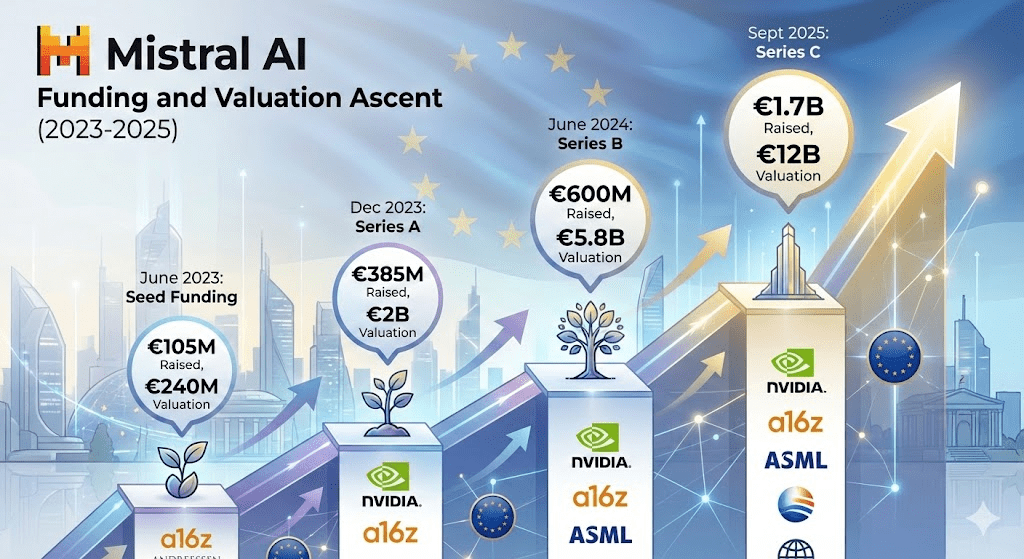
Im September 2025 schloss Mistral eine Serie-C-Finanzierung über 1,7 Milliarden Euro ab. Lead-Investor: ASML, der niederländische Chip-Equipment-Gigant, mit 1,3 Milliarden Euro für einen 11%-Anteil.
Die Bewertung: 11,7 Milliarden Euro. Rund 14 Milliarden Dollar.
Ein Revenue-Multiple von 93x bei geschätzten 60 Millionen Euro Quartalsumsatz. Zum Vergleich: OpenAI wird mit 20-30x gehandelt. Anthropic mit 40-60x.
Investoren zahlen hier keine Prämie für Technologie. Sie zahlen eine Prämie für europäische Souveränität.
Was die Benchmarks nicht sagen
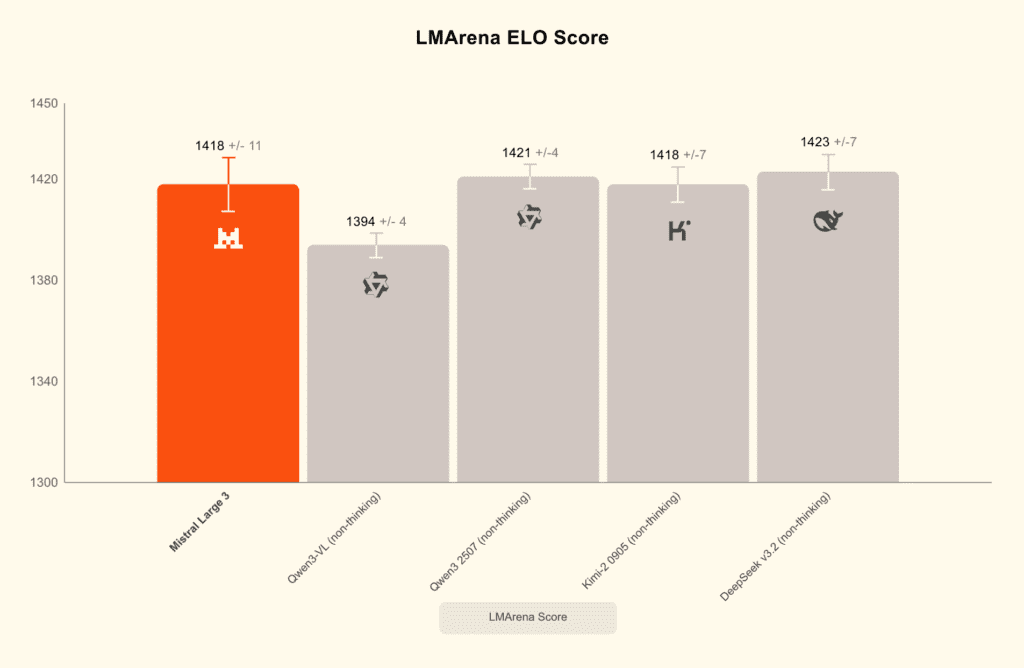
Hier ist die unbequeme Wahrheit: Mistral Large 3 ist nicht das beste Modell. Auf dem LMArena-Leaderboard sitzt es bei einem Elo-Rating von 1418 – hinter Qwen3-235B (1450+) und Deepseek v3 (1430+).
Aber die Benchmark-Obsession verschleiert die eigentliche Frage:
- Qwen3 ist closed-source. Alibaba kontrolliert es. In einem Handelskonflikt mit China – was dann?
- Deepseek v3 kommt aus China. US-Sanktionen können den Zugang blockieren.
Das ist nicht „besser vs. schlechter“. Das ist „kontrolliert vs. kontrollierbar“.
Distributed Intelligence: Philosophie oder Buzzword?
Arthur Mensch, Mistrals CEO und ehemaliger DeepMind-Forscher, nennt es „Distributed Intelligence“. Die These: Die Zukunft der KI liegt nicht in immer größeren zentralen Modellen, sondern in einem Ökosystem spezialisierter, verteilter Intelligenz.
Das klingt nach PR. Aber die technische Realität stützt es:
Edge-Deployment wird real. Ein 3B-Modell auf einem Smartphone. Ein 8B-Modell auf einer Drohne. Ein 14B-Modell in einem medizinischen Gerät. Keine Latenz. Kein Internet. Keine Cloud-Abhängigkeit.
Spezialisierung schlägt Generalisierung. Die drei Varianten (Base, Instruct, Reasoning) sind nicht kosmetisch. Ein Reasoning-Modell für analytische Aufgaben. Ein Instruct-Modell für Chat. Ein Base-Modell für Fine-Tuning. Verschiedene Probleme brauchen verschiedene Werkzeuge.
Regulierung erzwingt Dezentralisierung. Artikel 63b des EU AI Acts verlangt Transparenz für Hochrisiko-Anwendungen. Ein auditbares Open-Source-Modell erfüllt das. Ein proprietäres Modell – nicht ohne Gerichtsbeschluss.
Die Schwachstellen im Argument
Distributed Intelligence ist nicht Evangelium. Hier sind die Risiken, die Mistral nicht in die Pressemitteilung schreibt:
Quantisierung kostet Qualität. 4-Bit läuft auf 4GB VRAM. Aber 4-Bit ist nicht „keine Trade-offs“. Die Inferenz-Qualität sinkt messbar.
Edge ist nicht für alles. Komplexes Reasoning braucht Compute. Ein 3B-Modell wird keine wissenschaftlichen Paper analysieren.
40 Sprachen ≠ 40 gleich gute Sprachen. Englisch dominiert die Trainingsdaten. Für Swahili, Nepali, Quechua sind alle Modelle schlecht – auch Mistral.
MoE-Inference ist kompliziert. Routing-Overhead, irregular memory access, batching fragmentation – die „Effizienz“ von Sparse MoE ist theoretischer als praktisch.
Für wen ist Mistral 3 richtig?
✅ Ja, wenn:
- Daten in deinem Rechenzentrum bleiben müssen (Finance, Healthcare, Defense)
- Du Modelle fine-tunen und adaptieren willst
- Du in nicht-englischen Märkten operierst
- Kosten minimieren bei akzeptabler Qualität Priorität hat
- Du Open-Source regulatorisch brauchst
- Lokale Inference deployen willst (Edge, IoT, Embedded)
❌ Nein, wenn:
- Absolute beste Performance ohne Kompromisse nötig ist
- Du KI ohne eigene Engineers/Infrastruktur willst
- Performance-Differenz existenzielle Bedeutung hat
Epilog: Die unbeantwortete Frage
Am Ende des Mistral-3-Launches bleibt eine Frage, die keine Benchmark beantwortet:
Ist „Distributed Intelligence“ die Zukunft – oder eine Nische?
Wenn sie die Zukunft ist, hat Mistral sich positioniert, um sie anzuführen. Wenn sie Nische bleibt, haben die Investoren auf das falsche Pferd gesetzt, und die 14-Milliarden-Dollar-Bewertung ist Hybris.
Die Antwort wird nicht in Elo-Ratings entschieden. Sie wird in der realen Welt entschieden – in HSBCs Rechenzentren, in europäischen Regulierungsbehörden, in der Frage, ob Unternehmen wirklich bereit sind, die Kontrolle über ihre KI zu übernehmen.
Mistral hat die Technologie gebaut. Die Zukunft müssen wir noch bauen.
Weiterführende Links und Ressourcen
Offizielle Mistral AI Ressourcen:
- Mistral 3 Ankündigung: https://mistral.ai/news/mistral-3
- Mistral AI Studio: https://console.mistral.ai/
- Mistral GitHub: https://github.com/mistralai
- Mistral Dokumentation: https://docs.mistral.ai/
HSBC Partnership:
- HSBC Pressemitteilung: https://www.hsbc.com/news-and-views/news/media-releases/2025/hsbc-and-mistral-ai-join-forces-to-accelerate-ai-adoption-across-global-bank
Technical Deep Dives:
- NVIDIA Developer Blog zu MoE: https://developer.nvidia.com/blog/applying-mixture-of-experts-in-llm-architectures/
- NVIDIA Mistral Partnership: https://blogs.nvidia.com/blog/mistral-frontier-open-models/
- Mistral auf Amazon Bedrock: https://aws.amazon.com/blogs/aws/amazon-bedrock-adds-fully-managed-open-weight-models/
Benchmark und Vergleiche:
- LMArena Leaderboard: https://lmarena.ai/leaderboard
- Hugging Face Mistral Collection: https://huggingface.co/mistralai
Analysen und Kommentare:
- TechCrunch Coverage: https://techcrunch.com/2025/12/02/mistral-closes-in-on-big-ai-rivals-with-mistral-3-open-weight-frontier-and-small-models/
- VentureBeat Analysis: https://venturebeat.com/ai/mistral-launches-mistral-3-a-family-of-open-models-designed-to-run-on/
- Reuters HSBC Story: https://www.reuters.com/business/finance/hsbc-taps-french-start-up-mistral-supercharge-generative-ai-rollout-2025-12-01/
Community und Applications:
- Mistral Apps auf Lablab.ai: https://lablab.ai/apps/tech/mistral-ai
- Red Hat Integration Guide: https://developers.redhat.com/articles/2025/12/02/run-mistral-large-3-ministral-3-vllm-red-hat-ai